Introduction
In this document, based on couple of benchmark tests, the parallel performance and scalability of the CFD code FLUENT on the system VILJE will be shown. Simulations were performed up to 256 CPU cores, with the version 13.
The system
Vilje is a SGI Altix Ice X computer with 1404 nodes, each with two eight-core Intel Xeon E5-2670 CPU's and 32 GB of memory per node. The interconnect is FDR and FDR-10 Infiniband.
The test case
The chosen benchmark case is based on the simulation of external flow over a ship section with Large Eddy Simulation (LES). More details about the flow parameters and results can be found in Arslan, et al. [1]. The dimension of the ships sections, drafts and the gap between the ship sections are show in Table 1. The dimensions are in model scale 1:210. In Figure 1, the part of the computational domain close to the ship sections is shown. In the numerical simulations, A certain incoming flow velocity is considered as inlet boundary condition: 0.254 m/s . Reynolds numbers based on breadth of the large ship are 68000.
|
|
KVLCC (1) mm |
Aframax (2) mm |
|
|---|---|---|---|
|
Breadth (B) |
275 |
200 |
|
|
Draft (T) |
100 |
40 |
|
|
Bilge Radius (R) |
10 |
20 |
|
|
Gap (d) |
30 mm |
||
|
Water depth |
610 mm |
||
|
A |
160 mm |
||
Table 1: Dimensions of the computational domain in model scale. (1:210)
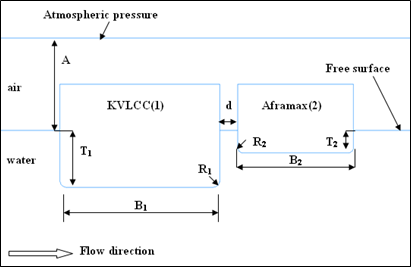
Figure 1. Details of the computational domain and ship dimensions.
The computational domain consists of two parts: water and air. Total number of elements is about 3 million in the total (air+water) domain. An unstructured hexahedral grid is used in the domain except near the ship sections. In order to capture sufficient mesh resolution inside the boundary layer (y+ <1), high aspect ratio structured elements are used as layers expanding from ship surfaces normal to the direction of the wall. The number of elements in spanwise direction is 30
Results
Simulations are performed for 500 time steps for each simulation. The time step size is 1x10-3 seconds. The performance is measured based on the average of wall clock time per iteration during the simulations. Figure 2 shows the performance of the FLUENT for the problem. For the mesh partitioning, the Metis method has been applied. The Y axis shows the number of iterations calculated per second during the simulation. The parallel efficiency is around %71 for the highest core number(256) and %81 for 128 cores. For lower number of cores the efficiency is relatively high, %87 for the 64 cores, %93 for 32 cores and %98 for 16 cores.
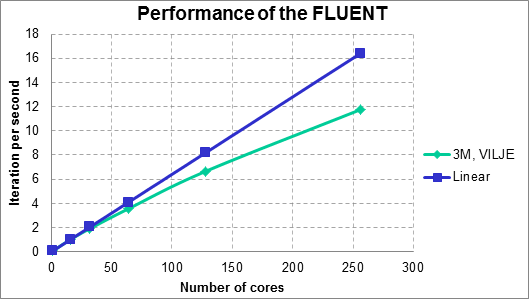
Figure 2. Performance chart for the flow around ship sections for 3M mesh.
Conclusions
This work demonstrates that FLUENT shows reasonable parallel performance and scalability for 3M mesh size. The mesh is course for Large Eddy Simulations on moderate Reynolds number flow. The scalability will be probably higher for larges meshes. It is necessary to repeat tests with different size of meshes with larger number of cores. More results from benchmark tests performed on different platforms are shown in ANSYS FLUENT official website [2]. Our results look identical with the ones made for external flow over a passenger sedan with 3.6 M mesh.
References
[1] Arslan, T., Pettersen, B., Visscher, J., Muthanna, C., and Andersson, H. I., 2011, "A Comparative Study of Piv Experiments and Numerical Simulations of Flow Fields around Two Interacting Ships," Proceedings of 2nd International Conference on Ship Manoeuvring in Shallow and Confined Water: Ship to Ship Interaction, Trondheim, Norway, pp. 31-37.
[2]ANSYS Fluent Benchmarks, http://www.ansys.com/Support/Platform+Support/Benchmarks+Overview/ANSYS+Fluent+Benchmarks