Introduction
In this document, based on couple of benchmark tests, the parallel performance and scalability of the CFD code Code_Saturne on the system VILJE will be shown. Simulations were performed up to 8192 CPU cores, with the version 3.0.1.
The system
Vilje is a SGI Altix Ice X computer with 1404 nodes, each with two eight-core Intel Xeon E5-2670 CPU's and 32 GB of memory per node. The interconnect is FDR and FDR-10 Infiniband.
Compiling options for Code_Saturne
Code_Saturne has several configuration options based on different libraries. In these tests, the code is built with Intel compiler version 13.0.1 by using SGI’s MPT version 2.0.6. In compilation, two different methods are used for partitioning of the solution domain: SFC (Space filling curve based) which is the default method for Code_Saturne and Scotch. MPI-IO is enabled and Intel’s MKL library for BLAS option is activated (more information can be found in ‘Installation of Code_Saturne’).
The test case
The chosen benchmark case was based on the simulation of the flow over a staggered tube bundle as a part of a nuclear reactor with Large Eddy Simulation (LES). The benchmark problem has been selected for evaluation of the parallel performance of PRACE Tier-0 systems and the comparative results can be found in Moulinec et al. [1].
In Figure 1 shows the computational domain, a subset of the tube bundle simulation. The tube diameter is D=22.7 mm and length is L= 64 mm. Reynolds number based on the bulk velocity and tube diameter (Re=UD/ν) is 18,000. The computational domain is created by extracting only one tube and the surrounding fluid part from flow field around the tube bundle. The faces of this domain are considered as periodic faces as seen in the figure.
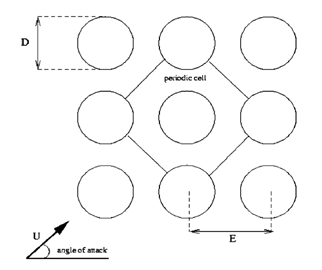
Figure 1. Flow over tube bundle


Figure 2. Mesh for one tube (left) and multiplied (3x3) mesh (right)
The resulting domain and the created mesh can be seen in Figure 2 (left). In this example, the mesh contains 12,805,120 hexagonal cells. The mesh for a single tube is copied in a formation (3x3) to create a bundle which can be seen in Figure 2(right). With this methodology, it is possible to reach over 200 million cells with a small effort. Code_Saturne is able to copy or multiply one single mesh zone to create larger domains or merge different mesh zones which are created separately. This process can be done in parallel to avoid memory overflows. More details about the flow parameters and mesh can be found in Moulinec et al. [1], Benhamadouche and Laurence [2] and Fournier et al [3]. In these benchmark tests, 4x4 (51 Million) and 16x16 (204 Million) configurations are used as seen in the next table.
|
Type of mesh |
Number of cells |
|---|---|
|
Single tube(original) |
12,805,120 |
|
2x2 full tubes |
51,220,480 |
|
4x4 full tubes |
204,881,920 |
Results
Simulations are performed for 100 time steps for each simulation. The time step size is 2x10-5 seconds. The performance is measured based on the average of wall clock time per each time step during the simulations. Figure 3 shows the performance of the Code_Saturne for the problem from 51M and 204M mesh. For 51M mesh, there are two partitioning methods have been applied. As seen in the Figure 3, the scotch method is not bringing any advantage especially on higher number of cores. For larger mesh (204M), simulations are not available for the scotch method for the moment. Scalability is measured and plotted in Figure 4. The Y axis shows the number of time steps calculated per second. For both partitioning methods, the parallel efficiency is relatively high for 1024 cores based on the 512 cores, around %90. For 2048 cores, the efficiency slightly drops to %67 for SFC and %77 for the scotch. For the highest number of cores, efficiency stays in a reasonable value of %48 and %44 for the SFC and the scotch respectively.
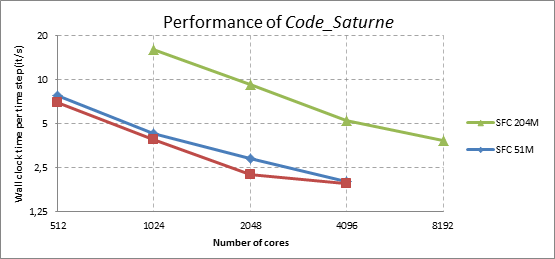
Figure 3. Performance chart for the flow around tube bundles for 51M and 204M mesh.
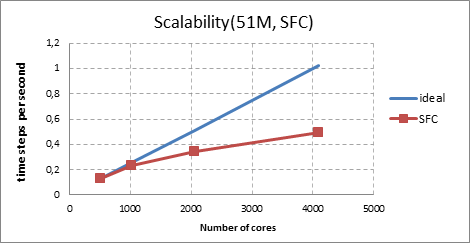
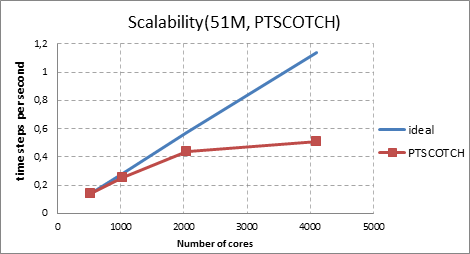
Figure 4. Scalability of the Code_Saturne for the flow around tube bundles with two different partitioning method (51 Million mesh)
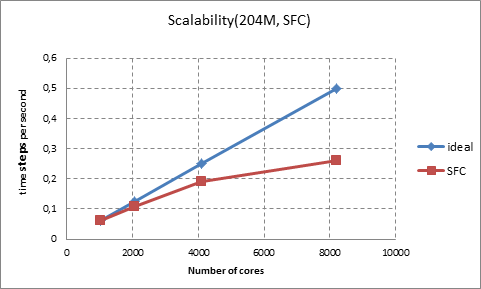
Figure 5. Scalability of the Code_Saturne for the flow around tube bundles with SFC partitioning method (204 Million mesh)
In Figure 5, Scalability is measured and plotted for the Code_Saturne based on SFC partitioning method with 204M mesh. The code scales up to 8192 cores with %52 parallel efficiency. For 4096 and 2048 cores, the efficiency based on 1024 cores is %76 and %86 respectively.
Conclusions
This work demonstrates that Code_Saturne looks ready for petascale calculations on VILJE. It shows reasonable parallel performance and scalability on range of 50-200M mesh size. It is a useful tool for Large Eddy Simulations on moderate Reynolds number for industrial flow problems and academic research. The mesh multiplication ability is also bringing ability to create large meshes have billion cells and the code can be a good alternative to other open-source CFD codes.
This version is the latest production version. Intermediate versions are released with couple of updates. Evaluation of the performance of the newer versions will come up soon. More benchmark tests are also possible for 800M mesh.