- Introduction
- The model and GPU solver
- The solver running on GPU
- GPU Performance
- Flow Results
- Conclusion and Future Work
- References
Introduction
The present work reviews calculations of a steady state three-dimensional (3D) flow past a centrifugal pump with its diffuser channels using different hardware platforms. The open source CFD software OpenFOAM has been ported to the GPU platform and simpleFoam solver is used in the calculations. The performance of a high-end GPU was reported. In this work, simulations were carried out at the best efficiency point (BEP) for single phase flow with four different turbulence models. The results were compared with the performance report from the manufacturer. Only the realizable k-ε turbulence model has been taken into account for performance tests. One characterization of the flow passed the same multistage pump has already been achieved in previous works using commercial Ansys Fluent software [1]. In this work, the open-source software RapidCFD [2] has been used. The code is based on OpenFOAM [3] solvers which are running on GPU cards rather than CPUs. The performance gain of GPUs over CPUs has been studied for the simulated case which is a steady three dimensional (3D) flow past the diffuser channels of a centrifugal pump.
The model and GPU solver
It is a three-stage end suction centrifugal pump for produced water. The computational domain consists in the inlet pipe, the first stage impeller and the first stage stator. After passing the stator, the fluid is addressed to the following stage by mean of return vanes. Figure 1 shows the cross-section of the pump's diffuser. The computational grid is structured along the pump axis direction with hexahedral cells in the diffuser domain. The grid has no size refinement along the walls since we believe that the resolution were fine enough to take into account the wall effects on the flow ( y+ is in the range 30 < y+ < 300). This allows us to use proper wall modelling in the calculation of the turbulence. Due to the complicated shape of the impeller vanes, the impeller grid is unstructured with tetrahedral cells. The total number of cells is about 10 millions (9,926,478 ) cells. The distribution of the cells in the different zones of the computational domain is summarized in Table 1.
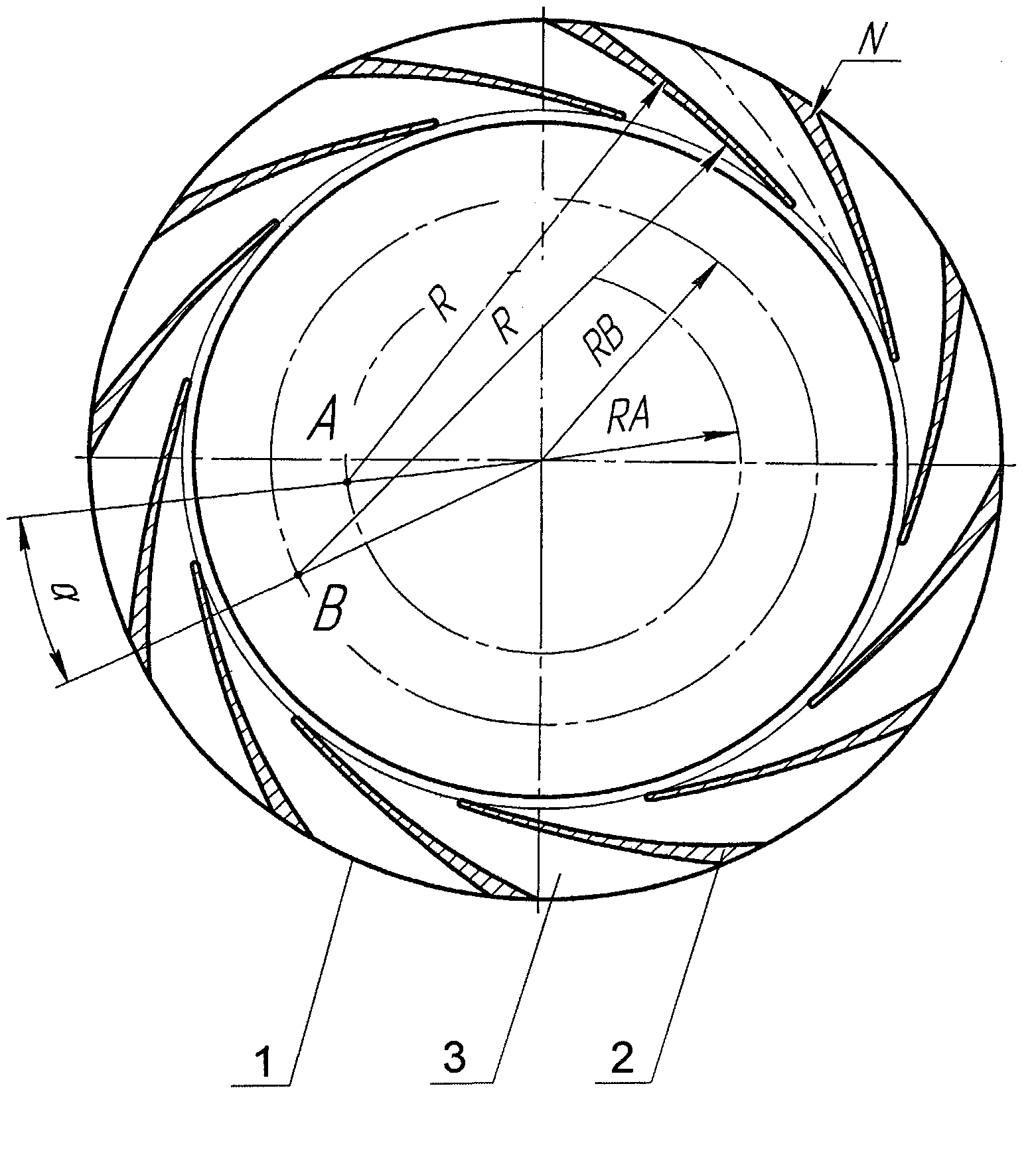
Figure 1: Illustration of the pump impeller and diffuser
|
Zone |
Type of grid |
Number of Cells |
|
Inlet Pipe |
Prismatic |
359,588 |
|
Impeller |
Tetrahedral |
3,464,380 |
|
Diffuser |
Hexahedral |
6,102,510 |
Table 1: Mesh cells distribution
The solver running on GPU
RapidCFD is a CUDA-ported version of a Finite Volume Method based code OpenFOAM, that runs all simulation stages on Graphic Processing Units (GPU). Running entire simulation on the GPU has a significant performance advantage over commonly used GPU acceleration of solvers for linear equation systems. With the full acceleration, there is no need for constant memory copying between CPU and GPU memory space which is a huge bottleneck that significantly decreases overall simulation speed. Due to a very good design and modularity of open source code OpenFOAM, porting it to a different architecture was simplified. Modifying an existing code was beneficial over writing a new one, since with relatively small effort on multiple functionalities like turbulence modelling, wide range of boundary conditions and coarse grained parallel processing were available.
Porting OpenFOAM requires identification and modifications of some parts of the code that are responsible for most computationally intensive tasks, such as matrix assembly and solution. This requires creating data structures for storing all required information in GPU memory. A disadvantage of using GPUs is that all algorithms need to be parallelized. For this reason, the most efficient smoother algorithm - Gauss-Seidel - had to be replaced with a less efficient weighted Jacobi. For the same reason only relatively poor diagonal (Jacobi) preconditioner from the original implementation was ported to GPU. In order to improve performance of solvers based on Krylov subspace method, a new fully parallel preconditioner AINV [4] was implemented. This new method offers some performance improvement over the diagonal preconditioner, however it is still less effective than original Incomplete Cholesky and Incomplete LU algorithms. Despite the disadvantage of using less efficient algorithms, simulations on the GPU cards run significantly faster than on multi-core CPU.
GPU Performance
In the GPU cluster we have used, CPUs are Intel Xeon E5-2670 with 8 cores working at 2.60 GHz. The graphics cards are NVIDIA GeForce Titan X with 3072 CUDA cores and 12 GB GDDR5 memory. At each node, there are two cards installed via PCI Express connection and two CPUs. In this work, a single node is used. The cluster systems used in this work are Vilje and Kongull located in Trondheim, Norway and Abel [5] which is located in Oslo, Norway.
The performance tests were made by RapidCFD's turbulentsteady state solver: simpleFoam. Both Geometric Algebraic Multigrid solver (GAMG) and Preconditioned Conjugate Gradient (PCG) solving for pressure equation were tested on both CPU and GPU in double precision. Solving velocity and turbulent quantities is not having a signicant role in computational effort therefore the solution method of pressure equation was focused more. As mentioned in the previous section, available preconditioner of PCG solver is AINV in RapidCFD (GPU) while standard OpenFoam solver (CPU) was using Diagonal Incomplete-Cholesky (DIC) which is the fastest one available. GAMG is using Gauss-Seidel smoother algorithm in OpenFOAM and Jacobi algorithm was used in RapidCFD. In the tests, simulations ran for 2 hours with several number of time steps (from 100 to 1000 based on the performance) and the first time step was discarded in the total wall time calculations. The convergence behaviour of the solver in the GPU simulations can be seen in Figure 4. As seen in Figure 5 the residuals are not fluctuating in CPU simulations. however the values for both simulations are smaller than 1e-5 for all equations.
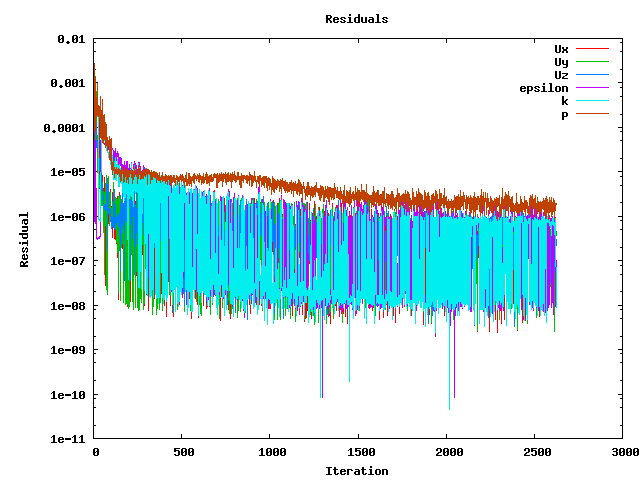
Figure 2. Residuals in the simulations (GPU)
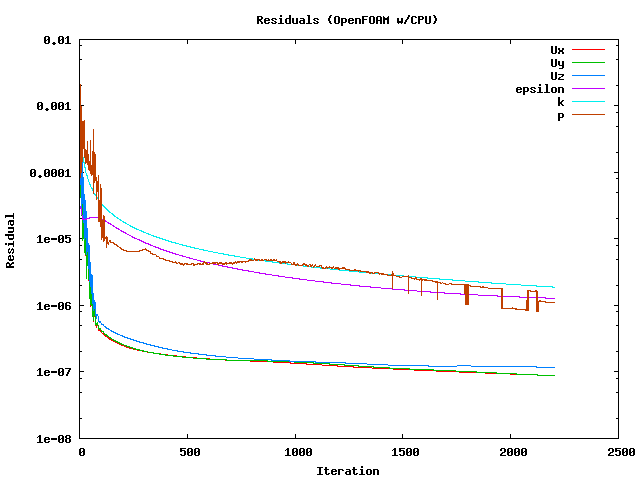
Figure 3. Residuals in the simulations (CPU)
The performance (calculated from wall clock time per iteration) for the GPU card (2 cards) over the 2 CPU unit (16 cores) is shown in Fig. 4. The GPU provided speed-up for PCG solver for two card is 3.4x which can be seen in Fig. 4. However, PCG is very slow compared to the GAMG solver for both GPU and CPU generally. In our case, GAMG shows superior performance over PCG as seen in Fig.4. At the same time, GPU gives 2.3x speed up for GAMG solver. However, GAMG solver requires larger memory than PCG, therefore, our case could not be handled at a single GPU card when GAMG was used. The tests were performed with two cards by using MPI for data communication between the cards. The results were compared to the performance with 2 CPUs for both PCG and GAMG solvers.
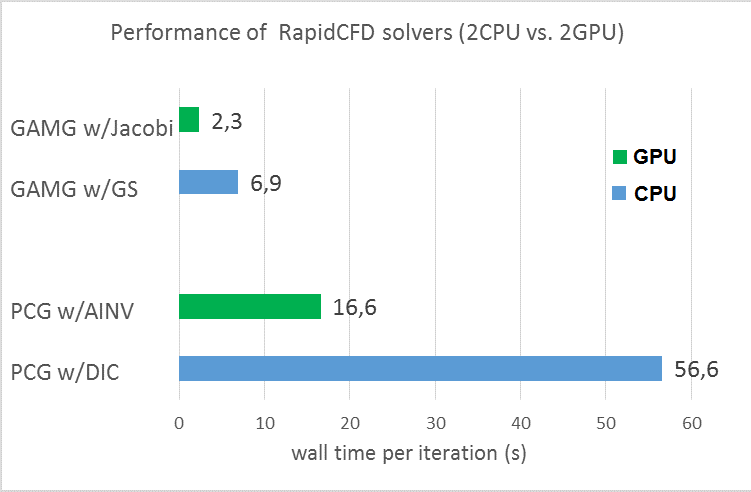
Figure 4. Performance of GPU versus CPU with different matrix solvers.
Flow Results
As the first part of the present work, we kept their focus on the turbulence modeling. The simulations are carried out at the best efficiency point (BEP) and single-phase flow. Four different turbulence models have been taken into account: k-ε (standard, RNG and realizable) and SST k-ω. For each model, the flow conditions have been calculated in steady state at best efficiency point (BEP). The resultant integral quantities (head, torque and efficiency) for each simulation have been compared to the data provided by the prototype manufacturer.
|
Head [m] |
Torque [Nm] |
Efficiency (%) |
|
|
Standard k-ε |
21.8 |
32.7 |
70 |
|
RNG k-ε |
22.6 |
32.5 |
73 |
|
Realizable k-ε |
21.2 |
30.2 |
74 |
|
SST k-ω |
20.7 |
29.5 |
74 |
|
TEST |
21.0 |
32.6 |
66.7 |
|
RATED |
20.3 |
31.9 |
69.0 |
Table 2: Integral quantities values for the different turbulence models
In Table 2, head, torque and efficiency for each considered turbulence models are compared with the manufacturer’s data. Data indicated as ”Test” are to be referred to the commissioning test carried out from the manufacturer on the whole pump. The differences in the head is acceptable. Concerning the internal flow in the diffuser channel, both the pressure and absolute velocity fields have been investigated. The overall ranges of velocities and pressures are the same, the flow structures are not affected by significant variation in the different turbulence models. In addition, there is not evident flow detachment. This means that the pump prototype is substantially well designed and explains the similarity of results in different turbulence models. According to these result, it is possible to state that for this simulation, the choice of turbulence model does not significantly affect the results. The comparison at this discharge level shows that the steady state model can approximate within 4-7% error the real flow characteristics. The same consideration can be done for the torque and the efficiency.
Conclusion and Future Work
This work aims to show that the new hardware platforms can be used for simulations at the industrial level and to demonstrate their importance for the future of CFD. The results demonstrates that OpenFOAM based RapidCFD shows promising speed up (around 2.6-3.5) with NVIDIA’s GeForce Titan X graphics cards versus Intel Xeon E5-2670 CPU units for calculations in double precision. It brings significant advantage for simulating the flow because of the faster convergence in solving the pressure equation. However, the memory of the GPU cards is limited and it can be a bottleneck for simulating larger cases. Thus, simulation with multi-GPU cards will be necessary.
References
[1] A. Nocente, T. Arslan, and T. K. Nielsen, “Numerical Prediction of a Multistage Centrifugal Pump Performance with Stationary and Moving Mesh”. Proceedings of ASME 2015 Power Conference 2015 (pp. V001T13A002-V001T13A002)
[2] OpenFOAM, http://www.openfoam.com/
[3] RapidCFD, https://sim-flow.com/rapid-cfd-gpu/
[4] Labutin Ilya B., Surodina Irina V., "Algorithm for Sparse Approximate Inverse Preconditioners in the Conjugate Gradient Method", Reliable Computing 19, 2013.
[5] Abel computer cluster, http://www.uio.no/english/services/it/research/hpc/abel/